7장.정보검색모형(확률검색)
확률검색: 확률 이론을 사용하여 질의에 대한 문헌의 적합성을 산출하는 검색 기법
가정
- 각 문헌은 주어진 질의에 적합하거나 부적합하다
- 한 문헌에 대한 적합성 판정은 다른 문헌과는 독립적이다
위 가정을 바탕으로 하는 확률검색 모형은 문헌이 적합할 확률과 부적합학 확률을 이용하여 문헌의 적합성 순위를 결정함
적합문헌: P(W∣X)>P(W-bar|X)
- P(W|X): 문헌 X가 질의에 적합할 확률
- P(W-bar|X): 문헌 X가 질의에 부적합할 확률
위같은 방법은 직접산출이어려움으로 베이즈 정리이용하여 변형
P(W∣X)=P(X)P(X∣W)/P(W)
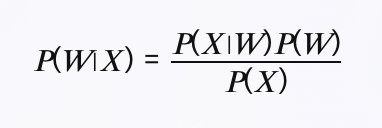
- P(X|W): 질의에 적합한 문헌 집합에서 문헌 X가 선택될 확률
- P(W): 질의에 적합한 문헌이 전체 문헌 집합에서 차지하는 비율
- P(X): 전체 문헌 집합에서 문헌 X가 선택될 확률

이 함수는 문헌 x가 질의에 적합할 확률과 부적합할 확률의 비율을 로그로 변환한 값으로 문헌x가 클수록 질의에 적합하다고 판단

*** Binary Independence Model (BIM)이라는 정보 검색 모델에서 사용되는 확률
BIM은 문서와 질의를 이진 벡터로 표현하고, 단어의 존재 여부만을 고려하는 모델
pi는 문헌 X가 적합문헌일 때 색인어 ti가 부여될 확률이고, qi는 문헌 X가 부적합문헌일 때 색인어 ti가 부여될 확률
즉, pi = P(xi=1|w1), qi = P(xi=1|W-bar)
문헌 X가 적합문헌일 때 색인어 ti부여되지않을 확률 = (1-pi)
문헌 X가 부적합문헌일 때 색인어 ti가 부여될 확률 = (1-qi)

pi,qi추정방법 -> 데이터베이스 내 문헌들의 적합성 정보이용 : 2x2 분할표이용

N: 데이터베이스 내 전체 문헌 수
R: 질의에 대한 적합문헌 수
n: 단어 ti 를 색인어로 갖는 문헌 수
r: 단어 ti 를 색인어로 갖는 적합문헌 수
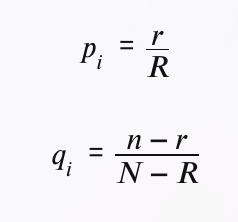
pi = 색인어 ti가 부여될 확률 / 적합문헌일때
qi = 색인어 ti가 부여될 확률 / 부적합문헌일때

*. 적합성 정보가 준비되어 있지 않을 때,
1. groft and harper의 전략 : 적합성 정보가 준비되어 있지 않을 때, 적합성 확률을 추정하기 위한 방법
g(x) = Σᵢ₌₁ᴹ xᵢ log(N-nᵢ/nᵢ) *nᵢ는 질의어 i를 포함하는 문헌 수를 의미
2.okapi시스템의 BM25 사용
언어모형검색기반: 언어모형을 활용하여 질의-문헌간 유사도 측정
색인어로 표현된 문헌모형으로부터 특정 질의를 생성할 확률을 산출하여 순위화 시키는방법

- t는 용어
- d는 문헌
- tf(t,d)는 문헌 d에서 용어 t의 빈도
- |d|는 문헌 d의 길이
이 식은 문헌 d에서 용어 t가 나타날 확률을 문헌 d의 길이로 정규화한 것. 즉, 문헌 d에서 용어 t의 상대적인 빈도를 의미
복수의 질의가 나올경우

**미출현 빈도가 발생하여 0이 되는경우
1.TF에 CF를 추가하여 방지
2. Jelinek-Mercer방법

P(t|C) :장서빈도
파라미터 : 두항의 비중을 나타냄 (디폴트값:1500)